
Here, we have explained the tesseract mex and MATLAB OCR (tesseract) function. Compared the both results with different images. We have compared the performance of the both OCR engine.
Tesseract mex
It has three input variables. The output of the mex variable only has the converted text. This mex was built by tesseract 3.01.
Below link contains the tesseract dependency files, unzip and place the file in C drive. Include the folder path in the system path.
Please click the below link. It contains tesseract 32bit and 64bit.
1) Image- Input image should be in 2-dimension uint8 format.
2) Language- eng,jpn…etc
3) Page Segmentation Mode
| 0 = Orientation and script detection (OSD) only. |
| 1 = Automatic page segmentation with OSD. |
| 2 = Automatic page segmentation, but no OSD, or OCR |
| 3 = Fully automatic page segmentation, but no OSD. (Default) |
| 4 = Assume a single column of text of variable sizes. |
| 5 = Assume a single uniform block of vertically aligned text. |
| 6 = Assume a single uniform block of text. |
| 7 = Treat the image as a single text line. |
| 8 = Treat the image as a single word. |
| 9 = Treat the image as a single word in a circle. |
| 10 = Treat the image as a single character. |
MATLAB OCR
1) Image
2) ‘Language’
3) ‘English’ (or) other languages
4) ‘TextLayout’
5) ‘Auto’ or ‘Block’ or ‘Line’ or ‘Word’
Text Layout Types
| Auto | Automatic Page Segmentation |
| Block | Assume a Single Uniform Block of Text |
| Line | Treat the image as a Single Text Line |
| Word | Treat the image as a Single Word |
Please refer the below link for a brief explanation.
MATLAB Code
%% reading input image %%
rawImage=imread(‘sampleImage.jpg’);
%% converting the input image into grayscale image %%
if size(rawImage,3)==3
grayImage=rgb2gray(rawImage);
else
grayImage=rawImage
end
%% tesseract function calling %%
Text=tesseract(grayImage’,’eng’,3);
%%In build OCR function %%
Text0=ocr(grayImage,’Language’,’English’,’TextLayout’,’Auto’);
Performance Analysis
The document was scanned at 200 dpi, it has been used for Based on our analysis tesseract mex takes less time for OCR ( 216 DPI Document ). But it is not providing the confidence score and coordinates of the texts. Tesseract accuracy was lesser than the MATLAB OCR.
| Tesseract Mex | MATLAB OCR | |
| Extraction Time | 3.798140 seconds. | 4.210153 seconds. |
| Character Level Confidence Score | No | Yes |
| Character Coordinates | No | Yes |
| Word Level Confidence Score | No | Yes |
| Word Coordinates | No | Yes |
Input Sample used for testing:
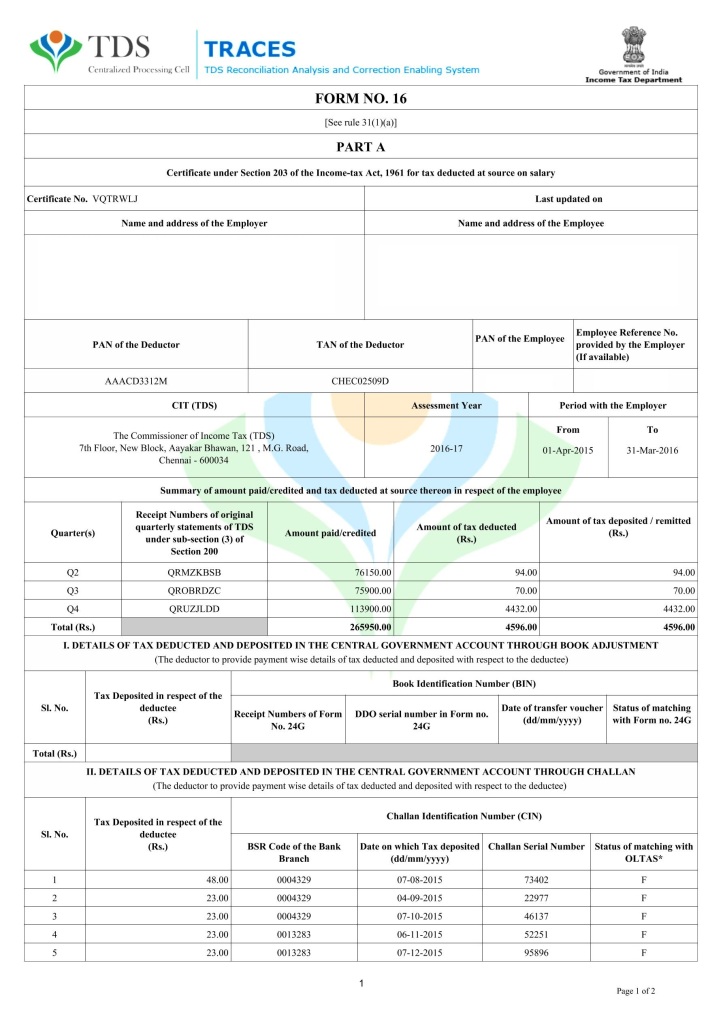
Please find the below tesseract mex output file.
Please find the below MATLAB OCR output file.
